
Всё ещё извлекаете данные из PDF-файлов вручную? А ведь для этого умные люди давно уже используют парсеры, которые помогут не только легко извлечь информацию из файла, но и привести её в божеский вид (структурировать).
Parsio
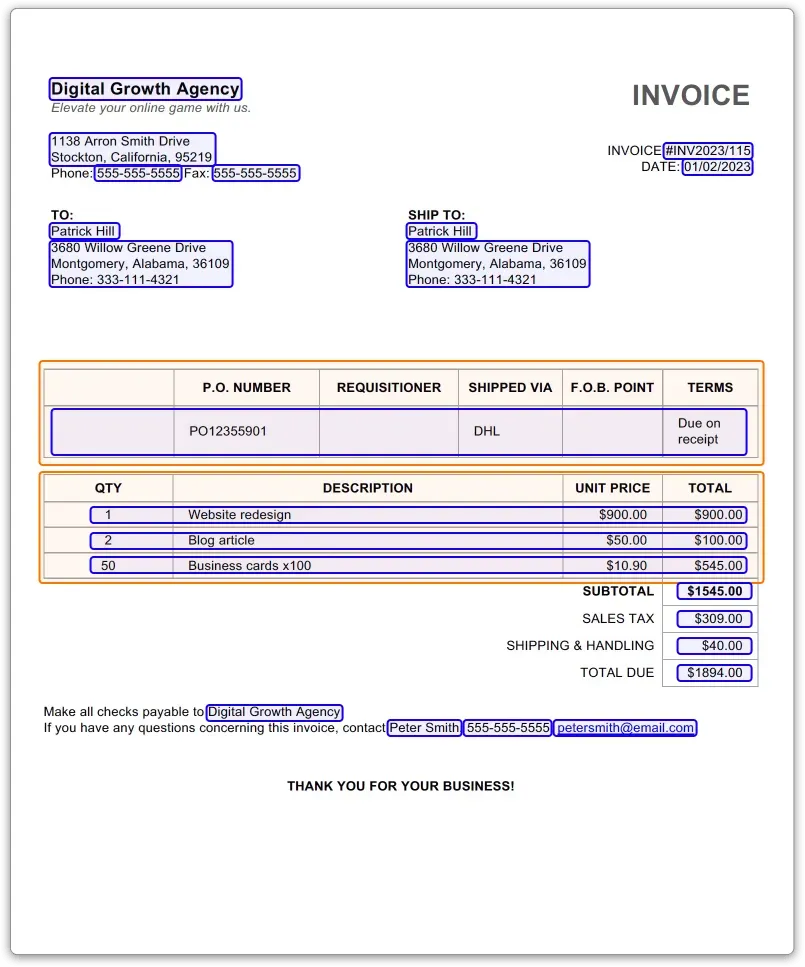
Нейронка для парсинга различных типов документов: электронные письма, PDF-файлы, рукописный текст и прочее. Есть поддержка GPT, что удобно при извлечении данных из неструктурированных документов.
Также этот парсер умеет обрабатывать сразу несколько PDF-файлов одновременно. И он работает с документами, написанными на разных языках мира.
Вы можете использовать шаблоны для автоматического извлечения данных из электронных писем. И можете взаимодействовать с различными сервисами (Google Sheets, Slack, Dropbox, Zapier, Make и пр.).
Несмотря на простой и понятный интерфейс Parsio, у некоторых пользователей могут возникнуть сложности при работе с продвинутыми функциями и настройками сервиса.
Airparser
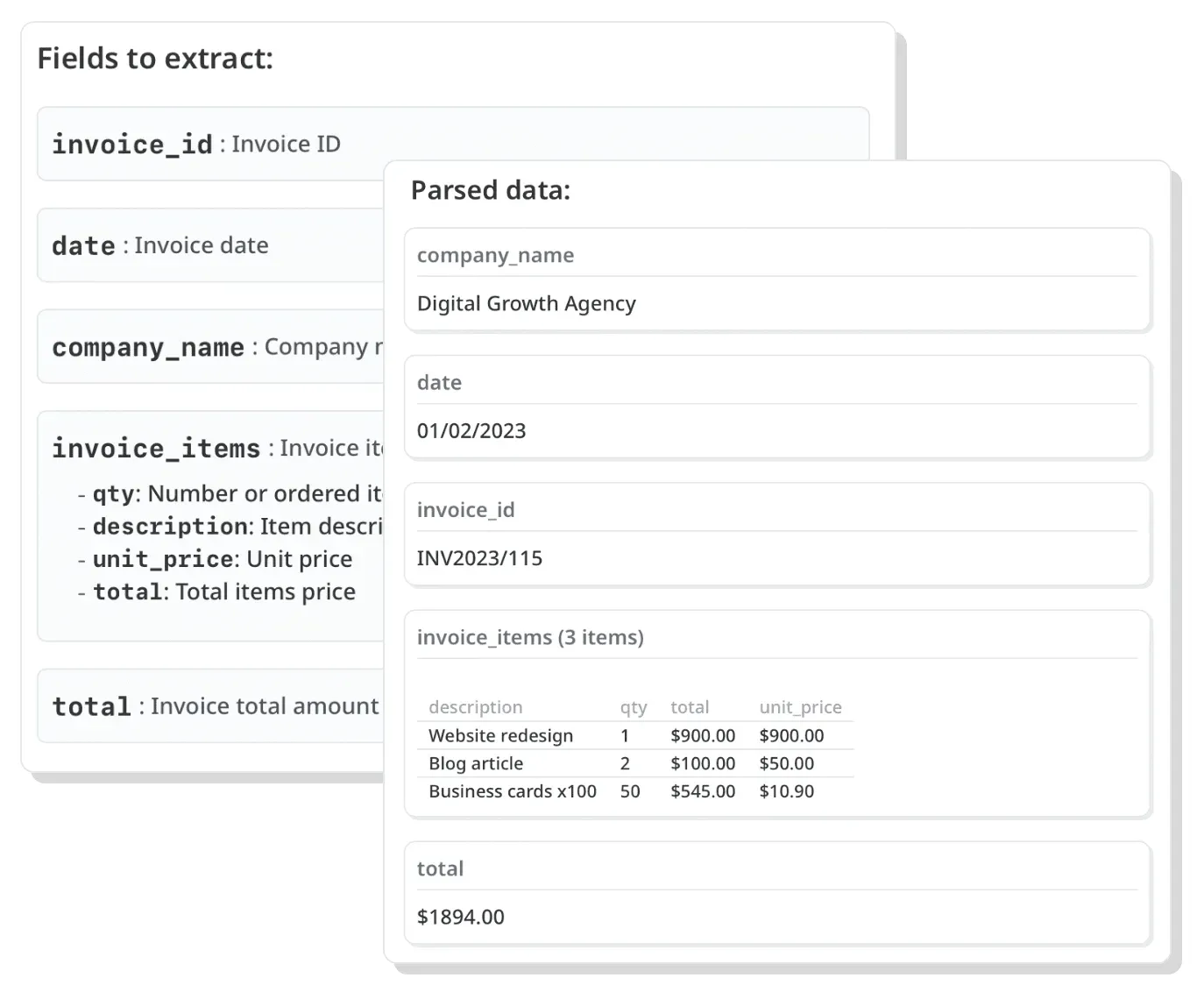
Ещё один парсер, который способен автоматизировать процесс извлечения данных из электронных писем, PDF и документов. Тоже работает на базе GPT, но более мощный, чем Parsio.
Вы можете настроить правила для точного извлечения информации. Также Airparser позволяет легко работать со сторонними приложениями и платформами, такими как Google Sheets, QuickBooks, Xero, Slack, Zapier, Make и многими другими.
Минусом сервиса можно назвать отсутствие бесплатной версии (есть только триал с 30 кредитами для парсинга).
Nanonets
Тоже неплохой сервис для извлечения данных из неструктурированных документов для их последующей структуризации. Подходит для работы с большим объёмом документов. Он может извлекать информацию из PDF-файлов, электронных писем, счетов-фактур, квитанций и прочих отсканированных документов.
Nanonets предлагает настраиваемые шаблоны для точного извлечения данных, а также бесшовную интеграцию с бизнес-системами через API-интерфейс.
Из минусов — нет GPT. Также этот парсер не подходит для бесплатного использования, так как сильно урезал возможности своей free-версии. Стоимость платной версии начинается от $499 в месяц, что не всем по карману.
Docparser
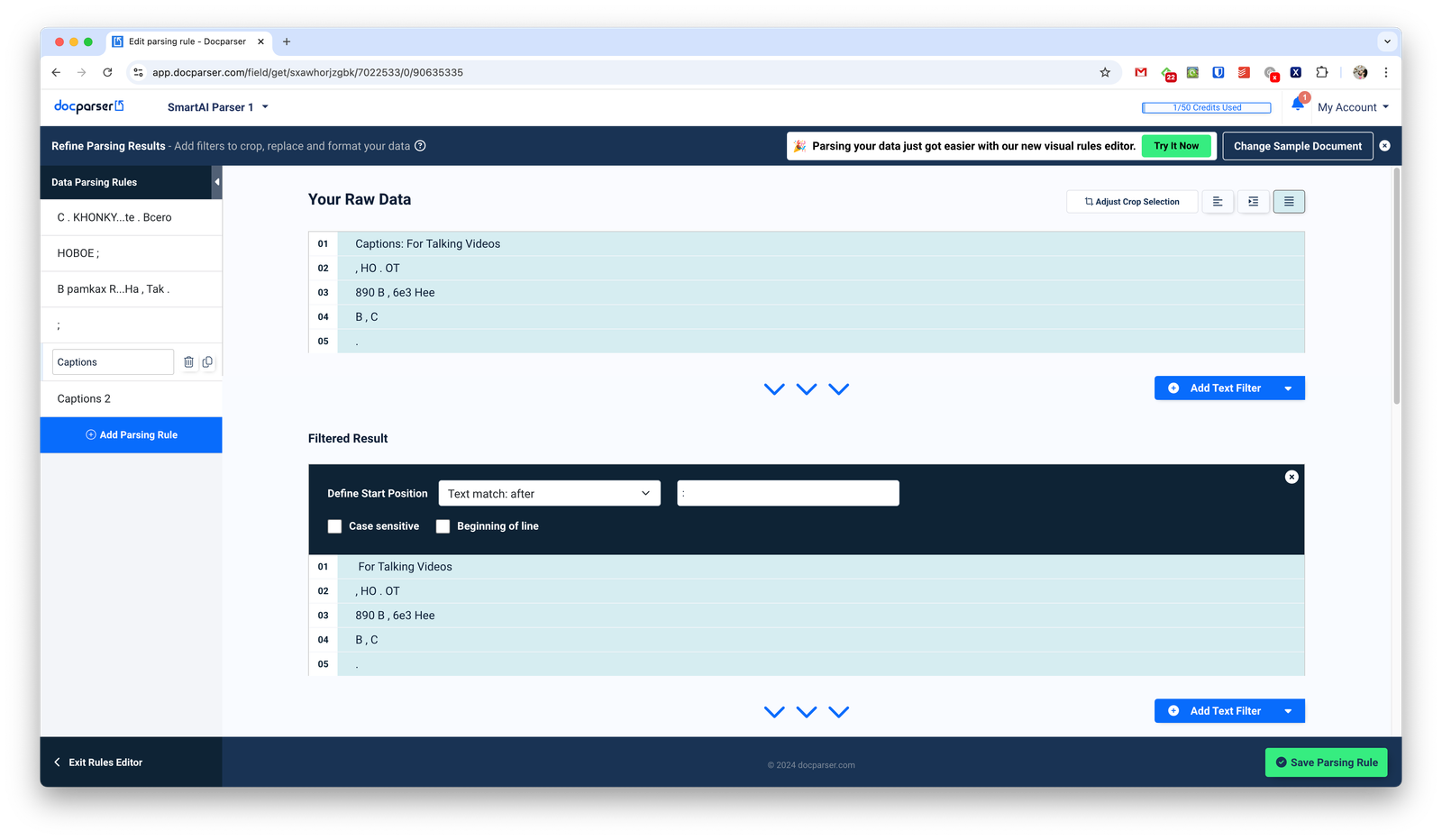
Единственный парсер из этой подборки, который работает не на ИИ, а на технологии Zonal OCR. Это значит, что он умеет извлекать информацию только из PDF, Word-документов и изображений.
Вы сможете подключать различные сторонние приложения и платформы. Также вы можете под каждый документ создать свой шаблон извлечения данных (правда, это не совсем удобно).
Из минусов я бы выделил устаревший интерфейс сервиса и то, что он не работает с электронными письмами, Excel и другими типами документов.
От $39 в месяц, есть бесплатный 14-дневный триал.
Docsumo
Ещё один сервис с ИИ для лёгкого извлечения данных из PDF, изображений, отсканированных документов, электронных писем и даже веб-сайтов.
Есть возможность использовать настраиваемые шаблоны для более точного извлечения информации из документов.
Также Docsumo легко интегрируется с существующими системами, такими как CRM, ERP и внутреннее ПО. И вы можете экспортировать данные в более удобные форматы, например в MS Excel или JSON.
Из минусов в первую очередь я бы выделил высокую стоимость. Также сервис может испытывать трудности при работе с более сложными документами. А ещё в нём не хватает некоторых продвинутых функций.
От $500 в месяц.
