

Данные (и особенно большие данные) играют огромную роль в современном цифровом мире. Они являются ценным активом, который позволяет компаниям принимать обоснованные решения, разрабатывать инновации, улучшать продукты и услуги, понимать потребности клиентов, оптимизировать бизнес-процессы и предсказывать тенденции на рынке.
Важно уметь собирать, анализировать и использовать данные эффективно, чтобы быть успешным и конкурентоспособным в современной цифровой экономике. Поэтому в этой статье я постараюсь простым языком и кратко пояснить за наборы данных, расскажу, где их найти и как с ними работать.
Что такое набор данных?
Давайте разберем основы
Датасет (Dataset), или набор данных, — это структурированная (не всегда) коллекция информации, которая нужна для анализа, исследования или обучения моделей машинного обучения. Такие наборы очень важны при работе с большими данными (Big data), ведь именно они являются основой для проведения различных вычислительных операций и аналитических задач.
Датасеты могут содержать данные разного типа, такие как числа, тексты, изображения, аудиофайлы и другие форматы. Обычно они представлены в виде таблиц. Каждый столбец описывает определённую переменную. А каждая строка соответствует отдельному наблюдению или примеру данных.
Какие бывают типы наборов данных
Существует множество типов подобных наборов, которые зависят от их характеристик и способа использования. Например, временные ряды, графовые, текстовые данные и многие-многие другие. Но в рамках этой статьи я остановлюсь на других трёх типах.
Структурированные данные — это чётко организованный набор данных, хранимый в базах данных, датасетах или таблицах, типа Excel. Обычные инструменты аналитики без проблем справляются с чтением такой информации. Преобразовать неструктурированные данные в структурированные — задача многих часов, но при использовании правильных инструментов вполне решаема. Например, можно использовать каталогизаторы данных, разметку данных, трансформацию и прочее.
Неструктурированные данные (или «сырые» данные), как правило, генерируются быстрее по сравнению со структурированными. Например, социальные сети создают сотни терабайт подобной информации в день. А ещё к таким данным можно отнести опросы клиентов, заметки, электронную почту.
Полуструктурированные данные — это такой середнячок, где хоть какая-то информация структурирована. Но анализировать её в таком виде всё ещё сложно. При приложении усилий — чистке от лишней информации — такие данные вполне можно попробовать загрузить в инструменты аналитики и работать с ними как обычно.
Где найти наборы данных?
Обзор различных ресурсов для поиска наборов данных
Существуют сотни, если не тысячи наборов данных. Среди них есть как платные, так и бесплатные. Поэтому важно знать ресурсы для их поиска.
Конечно, перечислить все из них просто невозможно. Поэтому я остановлюсь на небольшом списке, а дальше вы уж как-нибудь сами.
Quandl
Огромный репозиторий для экономических и финансовых данных. Многие датасеты бесплатные, но есть и платные.
Academic Torrents
Торренты полезны не только для скачивания киношки на вечер, но и для обмена датасетами. В данном случае — научными исследовательскими документами. Всё бесплатно.
Google Public Datasets
К кому обращаться за большими данными, как не к Google? У них есть датасеты по самым различным тематикам. Первый терабайт запросов — бесплатно.
Github
На GitHub полно репозиториев с публичными датасетами, и дать ссылку на каждый из них невозможно. Просто поищите, и вы обязательно найдёте что-то по вашей теме. К примеру, я рекомендую посмотреть на набор Awesome Public Datasets.
Kaggle
Маст-хэв ресурс, куда ходят все ребята, которые в теме. Здесь есть наборы больших данных по самым различным тематикам.
Bright Data
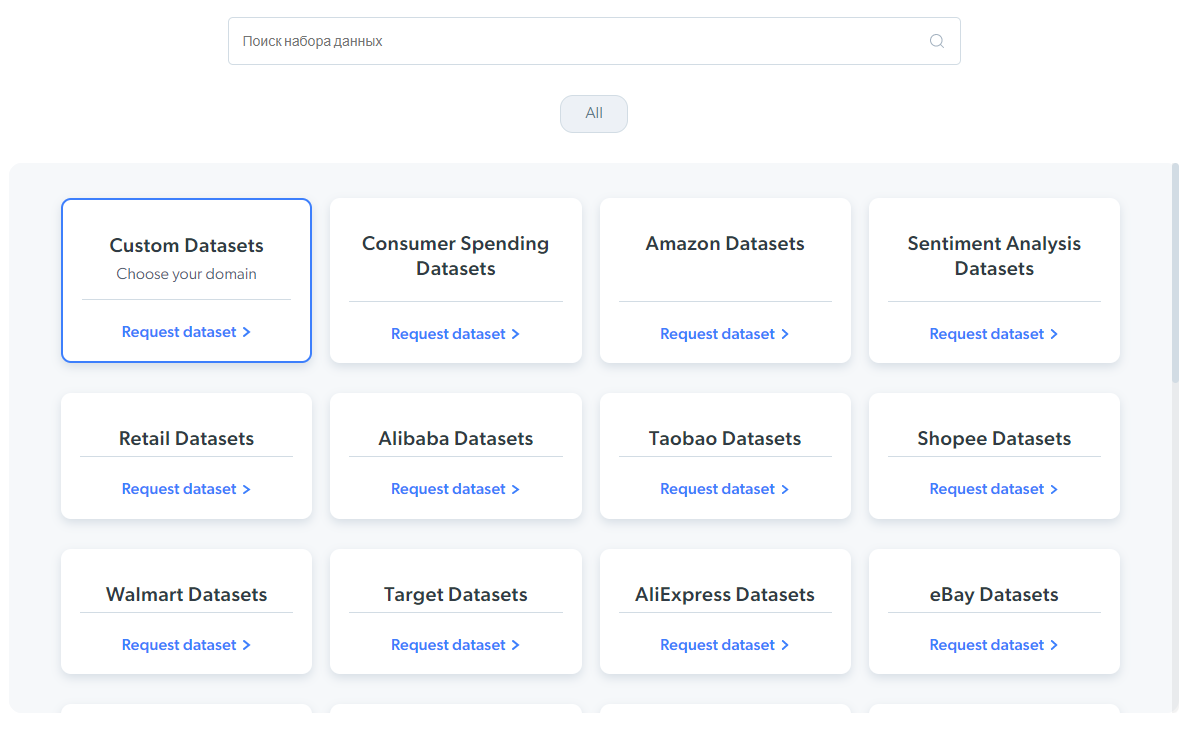
Это русскоязычный ресурс для поиска датасетов для различных целей. В ключевых отраслевых вертикалях можно запросить полный набор с целевого сайта, включая миллионы страниц и точек данных. С обновлением по запросу.
Либо запросить выборку из существующего набора данных по местоположению, категории или любому другому параметру, чтобы создать датасет, который содержит только необходимые вам данные.
Если нужного набора не нашлось, можно попросить его создать.
Где хранить данные
Вот мы обмазались данными, но где их хранить? Опять же для этого придуман далеко не один инструмент, но я выбрал пятёрку чисто на рандоме.
Greenplum
Очень популярная SQL БД с открытым кодом. Она заточена под работу с большими объёмами данных, из-за чего отлично подойдёт для аналитики Big data. Есть поддержка кластерной структуры серверов, выполнения нескольких тяжёлых запросов одновременно.
Cassandra
Инструмент от Apache с открытым кодом. Вообще, это NoSQL DBMS, которая предназначена для сбора и управления большими объёмами данных, распределённых между серверами. Многие компании выбирают Кассандру из-за простой масштабируемости.
MongoDB
NoSQL БД с открытым кодом, которая предлагает высокую масштабируемость и гибкость данных. Она обеспечивает дополнительное удобство благодаря своим возможностям построения запросов и индексирования. «Из коробки» предусмотрена возможность работы с БОЛЬШИМИ наборами данных, есть поддержка различных языков программирования и операционных систем.
MariaDB
Ещё одна популярная утилита для управления данными. Она превращает структурированную информацию в широкий массив приложений. Изначально MariaDB разрабатывалась как замена MySQL. Есть поддержка плагинов.
Apache Hadoop
Опенсорсный фреймворк для работы с биг датой, известный своей совместимостью и масштабируемостью. Есть возможность запуска из облака. Для работы не требуется мощное железо.
Как выбрать подходящий набор данных?
Если данных в наборе много, это ещё не означает, что они качественные. Но как понять, что является качественными данными? Если упростить, то — когда набор данных помогает решить проблему, которая вас волнует, значит, он является хорошим набором данных.
Однако при сборе данных полезно иметь более конкретное понимание качества. Вот некоторые аспекты, которые обычно соответствуют более эффективным моделям.
Надёжность. Означает, насколько можно доверять данным. Модель, обученная на надёжном наборе данных, вероятнее всего даст полезные прогнозы. При оценке надёжности важно учитывать следующее:
- Ошибки маркировки данных. Иногда люди допускают ошибки при разметке данных.
- Шумные данные. Некоторые измерения могут быть неточными или содержать шум. Это нормально в некоторой степени, но важно понять, какой шум допустим.
- Фильтрация данных. Нужно убедиться, что данные подходят для решаемой проблемы. Например, если вы создаёте систему обнаружения спама, то исключение поисковых запросов от ботов будет важным шагом.
Представление функции. Данные должны достаточно точно отражать задачу, которую вы пытаетесь решить. Например, если вы собираете данные о продажах, важно, чтобы они содержали достаточно информации о цене, количестве и других соответствующих атрибутах.
Минимизация перекоса. Перекос в данных означает неравномерное представление различных классов или категорий. Чтобы модель была более сбалансированной и точной, важно иметь достаточное количество примеров для каждого класса или категории.
Важно также понимать, что делает данные ненадёжными. Вот несколько примеров ненадёжных данных:
- Пропущенные значения. Некоторые данные могут быть неполными (например, если забыли ввести значение возраста дома).
- Повторяющиеся примеры. Иногда одни и те же данные могут быть загружены дважды по ошибке.
- Неверная разметка. Данные могут быть неправильно помечены или идентифицированы (например, если ошибочно названо изображение).
Итак, качество данных важно для достижения успешного решения бизнес-проблемы. Надёжность, правильное представление функции и минимизация перекоса являются ключевыми аспектами, на которые следует обратить внимание при работе с данными.
Как использовать наборы данных от Bright Data?
Давайте разберёмся на конкретном примере. Возьмём датасеты от Bright Data. На главной странице сайта в поисковой строке можно вбить название сета или вручную выбрать нужный из списка.
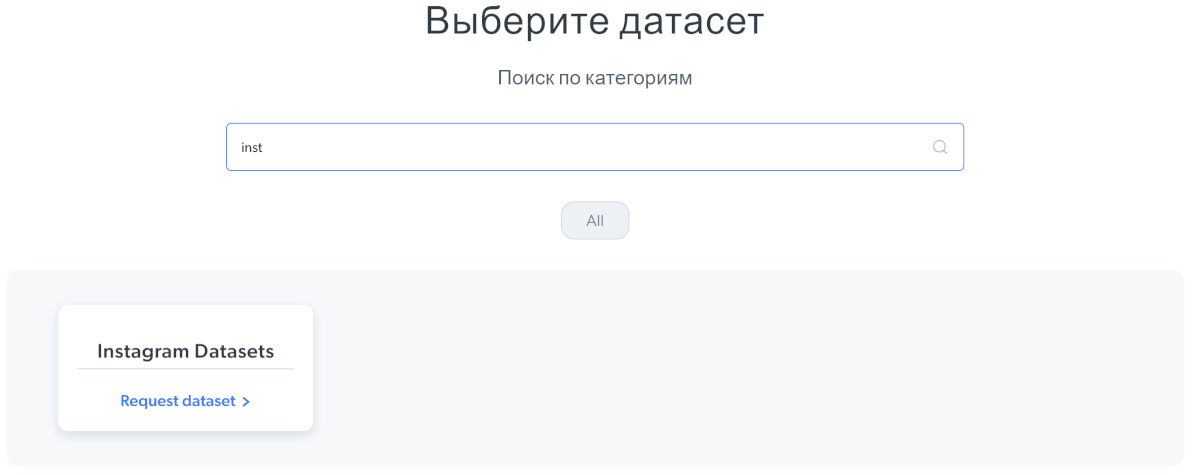
При нажатии на карточку вы перейдёте к его описанию, из которого можно понять, действительно ли этот набор подходит под ваши задачи.
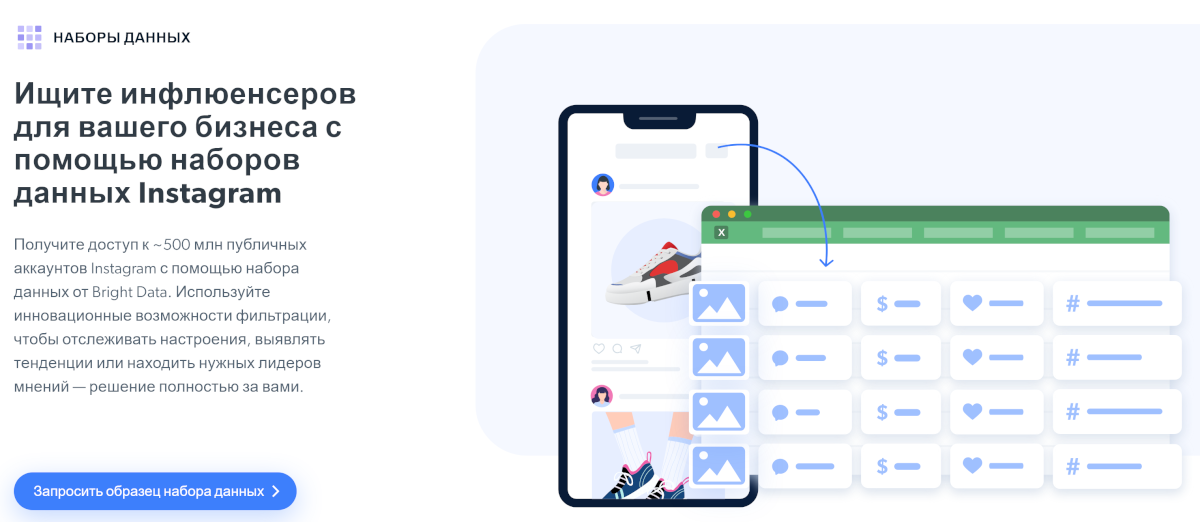
Ещё ниже можно посмотреть пример данных из набора. К сожалению, пример предоставляется в виде скриншота, и над ним не получится произвести никаких действий. А ещё он одинаковый для всех наборов.
Если вам кажется, что звёзды сошлись, остаётся нажать на кнопку Request dataset и заполнить форму. После чего с вами свяжется сотрудник компании и обсудит все необходимые детали, ответит на вопросы.
В чём плюсы наборов данных от Bright Data:
- Структура данных всегда является актуальной. При изменении структуры сайта для данных она тоже будет обновлена.
- Вы можете вывести только определённые пользовательские поля, а не работать со всеми данными.
- При обновлении данных в сете вы можете запросить обновление и вашей выгрузки.
- Несколько вариантов доставки: Amazon S3, Google Cloud PubSub, SFTP и Microsoft Azure.
- Различные форматы вывода: JSON, ndJSON, CSV или Excel.
- Масштабирование данных.
- Обеспечение качества данных.
Чем датасеты и биг дата полезны на практике
На первый взгляд кажется, что подобные штуки подходят только для очень крупных компаний. Но это не всегда так. Большие данные могут помочь принять обоснованное решение, улучшить бизнес-процессы, собрать информацию о потребностях и предпочтениях клиентов и многое другое.
Возьмём для примера сет Bright Data, созданный на основе ~500 млн публичных аккаунтов Instagram*. Большие данные могут вам помочь:
- Поиск инфлюенсеров: вы сможете отслеживать настроения, выявлять тенденции и находить лидеров мнений, которые имеют большую релевантность для вашего бренда.
- Мониторинг репутации бренда и настроений потребителей: Большие данные позволяют вам узнать, что говорят пользователи о вашем бренде, а также быстро определять изменения в популярности. Анализируя лайки, комментарии, хэштеги и другие метрики, вы сможете получить представление о том, как ваш бренд воспринимается и какие настроения преобладают среди потребителей.
- Отслеживание новых тенденций и возможностей: вы сможете найти новые тенденции, компании, профессионалов и продукты на рынке. Можно следить за активностями ваших конкурентов и быть в курсе последних разработок и изменений в отрасли.
- Поиск лучших инфлюенсеров: вы сможете определить лучших инфлюенсеров, которые помогут вам поделиться вашей историей и продвигать ваш бренд. Вы сможете оценить их вовлеченность, принадлежность к бренду, количество подписчиков, интересующие темы и другие параметры, чтобы выбрать наиболее подходящих партнеров для сотрудничества.
Все эти возможности, предоставляемые большими данными из Instagram, помогут вам принимать информированные решения, лучше понимать свою аудиторию и эффективно использовать социальную платформу для достижения ваших бизнес-целей. По этой ссылке можно купить базу данных инстаграм, описанную выше.
Поиск и выбор подходящего набора данных являются критически важными шагами в работе с данными. Важно не просто скачать подходящий по тематике сет, а убедиться в его полезности. Для этого стоит обратить внимание на качество данных и их поставщика. А также учесть эффективное использование ресурсов и вопрос доверия к полученным данным.
В случае с Bright Data можно быть уверенным в этих требованиях. Как я говорил выше, информация в датасетах постоянно подвергается обновлению и реструктурированию. Поэтому вы можете быть уверены в качестве получаемых данных.
При возникновении любых вопросов ещё до этапа покупки вы всегда можете связаться со специалистами из Bright Data по контактам, указанным на сайте.
Выводы
Большие данные – неотъемлемая часть успеха для любого крупного бизнеса или научного института. С их помощью можно лучше понять вашего клиента или увидеть скрытые процессы в компании. Главное научиться выбирать правильные наборы и интерпретировать их.
- Facebook и Instagram принадлежит Meta, организации, признанной экстремистской в Российской Федерации.