Я даже не читатель манги, но я могу представить, насколько муторно очищать speech bubbles от текста, если вы решили перевести её на русский или другой язык.
Для ребят на Линуксе есть отличный вариант — Panel Cleaner, который позволяет автоматизировать этот процесс с поддержкой OCR.
При первом запуске приложения потребуется дополнительная загрузка ML для определения и распознавания текста. Panel Cleaner справится с этой задачей самостоятельно, поэтому ничего искать и настраивать дополнительно не нужно. Но при необходимости вы можете использовать собственные OCR-движки.
Далее нужно просто добавить изображения (или папку с ними) и на левой панели настроить необходимые параметры обработки. Можно указать, как определять текст, препроцессор, подавление шумов и многое другое.
Затем для каждого элемента изображения нужно произвести генерацию. Так приложение сможет отделить текст, фон, пузыри и прочие штуки в отдельные маски.
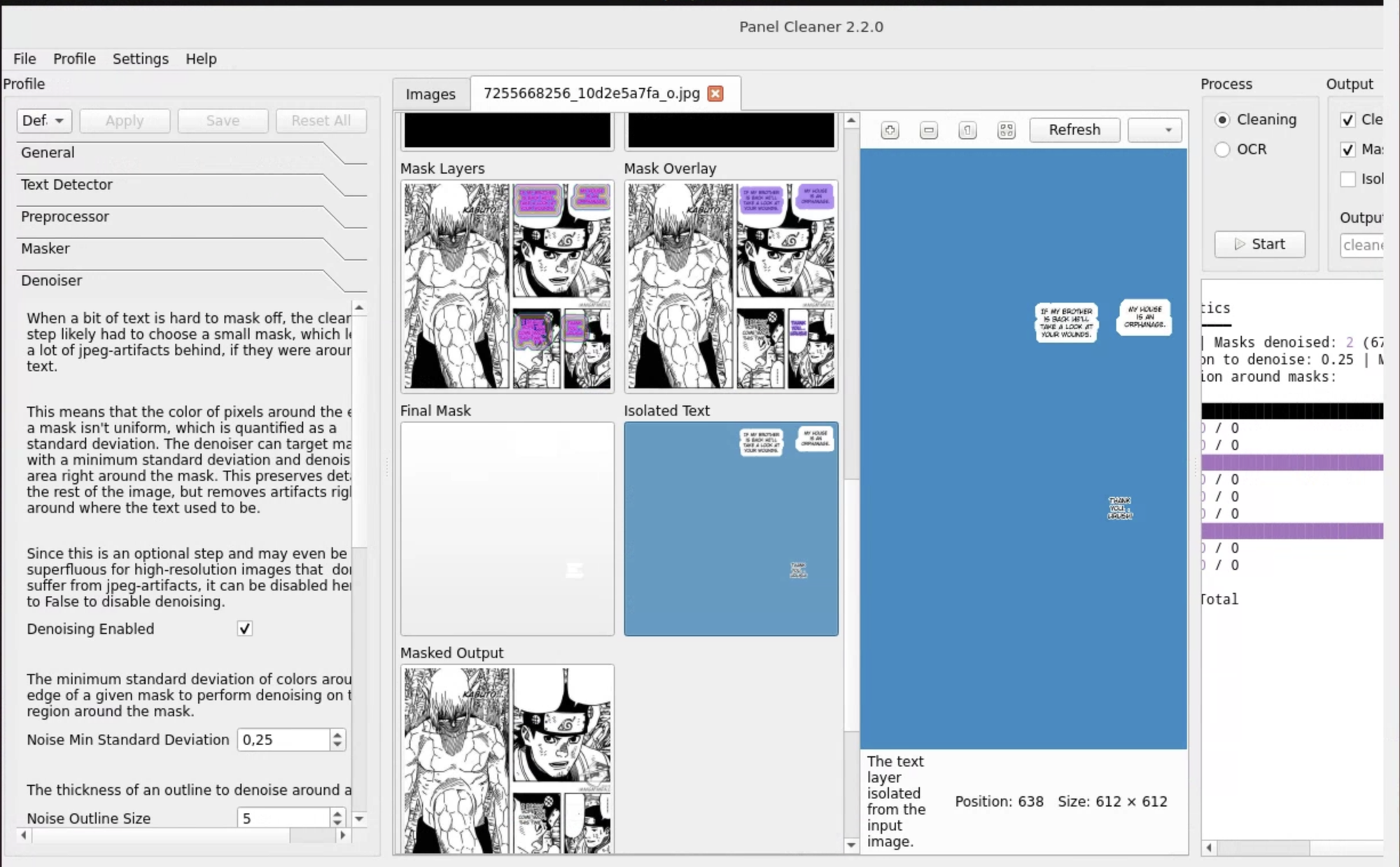
Править текст внутри приложения не получится, но сохранить окончательный результат с чистыми пузырями и распознанным текстом можно в отдельной папке. Результат очистки вы можете увидеть на изображениях ниже.
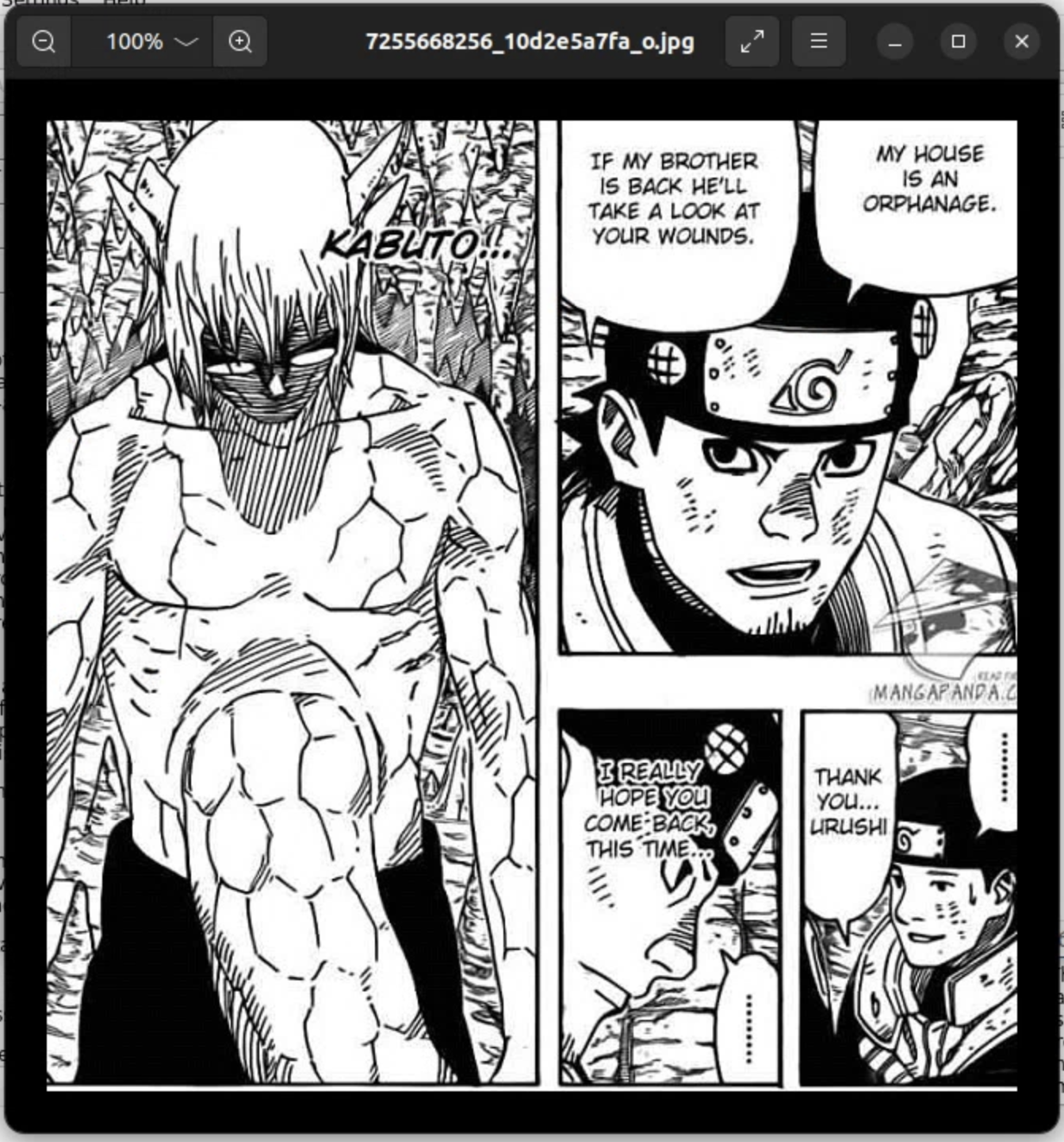
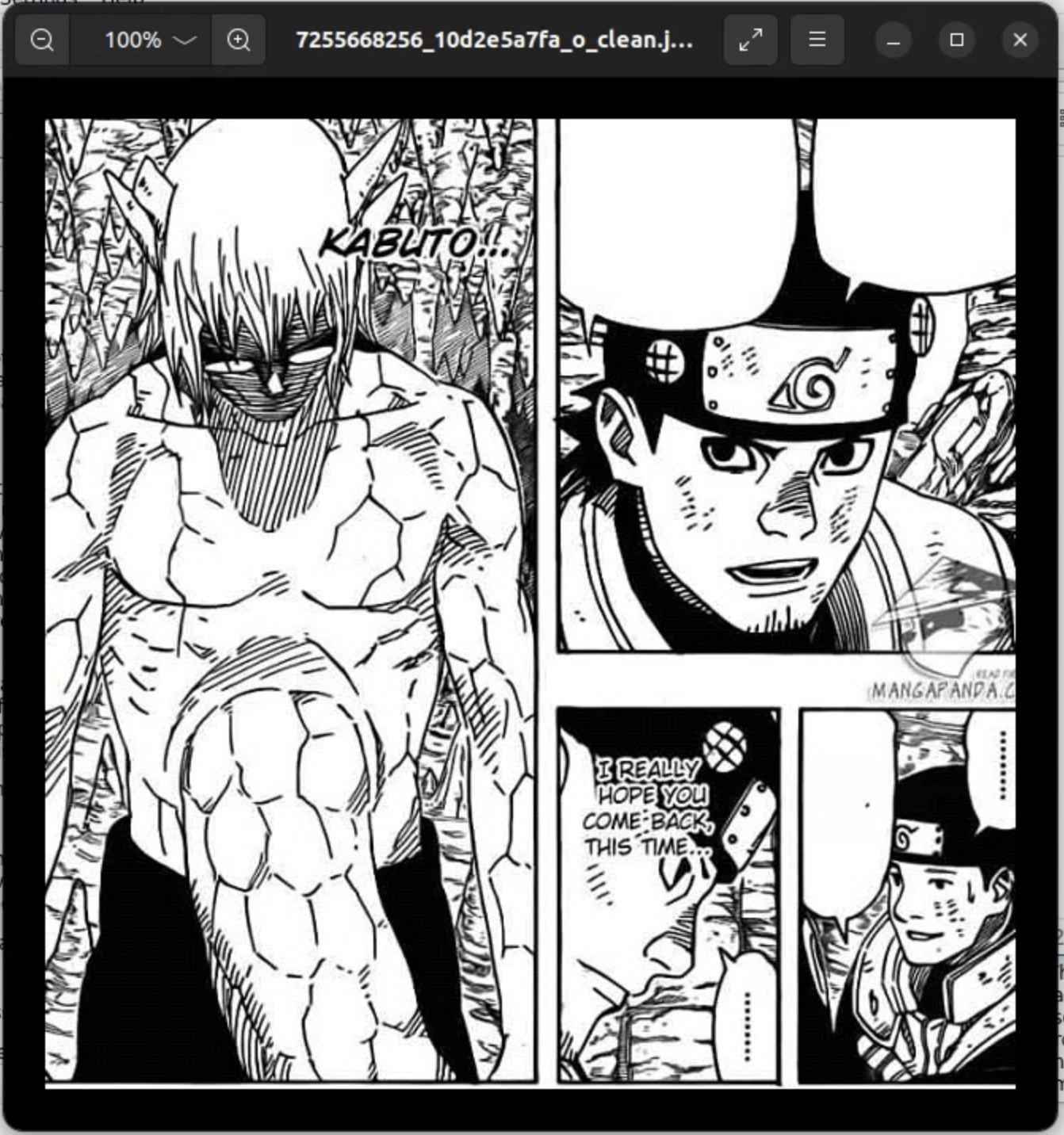
Как видно, текст именно из разговорных пузырей был удалён почти идеально. С текстом поверх изображений, естественно, ничего не получилось.
А вот распознать английский текст дефолтным движком с настройками по умолчанию у меня не получилось.