

В последнее время многие технические ресурсы пишут про большие данные (big data), интернет вещей (IoT) и нейротехнологии. С последними двумя пунктами списка всё ещё как-то понятно из названия. Но что значит большие данные? Жёсткий диск на терабайт с фотографиями — это Big Data? Ну, хорошо. А на два терабайта? Или Big Data это вовсе не про диски с информацией? Давайте вместе разберёмся и узнаем, чем это поможет обычным людям.
Что такое большие данные?
Не буду глубоко вдаваться в термины и определения, касающиеся Big Data. Моя цель не нагрузить вас информацией, а помочь понять, что же всё-таки такое Big Data.
Конечно, на все вопросы есть ответы на мудрой Wikipedia и вот, как она определяет большие данные:
Большие данные (англ. big data, [ˈbɪɡ ˈdeɪtə]) в информационных технологиях — совокупность подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence. В данную серию включают средства массово-параллельной обработки неопределённо структурированных данных, прежде всего, решениями категории NoSQL, алгоритмами MapReduce, программными каркасами и библиотеками проекта Hadoop.

Стало понятней, но лишь совсем немного. Если упростить это определение до минимума, то мы получим следующее. Представьте, что у вас есть несколько таблиц с данными. Если таких таблиц две или три и данные в них содержатся в одинаково строгом порядке, то всё отлично. Инструменты для обработки больших данных уже не нужны. Однако существует множество систем, которые автоматически собирают и генерируют терабайты или даже эксабайты данных каждый день или час. Эти данные не обязательно структурированы или приведены к общему стилю. Вот тут-то и возникает проблема с их обработкой.
Что создаёт Big Data?
В жизни большинства из нас не возникает потребность в обработке таких огромных объёмов данных. Тем не менее есть множество сфер, где такая обработка просто необходима. Например, метеорологические и сейсмические станции. Либо данные сотовых вышек, камер видеонаблюдения или даже сообщения в социальных сетях.
В действительности практически любая информация, которую можно собрать и обработать, может стать источником больших данных. Так что, как я говорил выше, диск с терабайтом фотографий тоже попадает в разряд больших данных.
Как обрабатываются данные
Обработать подобные данные на обычном компьютере или другими привычными нам средствами невозможно. И не только из-за их объёма, но и из-за большого различия входных данных. Поэтому было разработано несколько направлений по обработке Big Data:
- Data Mining — получение необходимых аналитических данных из имеющихся источников на основе уже существующих методов;
- Краудсорсинг — обработка или сбор данных при помощи нас с вами. Чаще, конечно, при помощи наших компьютеров и смартфонов;
- Машинное обучение — когда компьютеру даются уже существующие данные, на основе которых он производит вычисления для их применения в будущем;
- Искусственные нейронные сети и подобные инструменты. Представьте себе супермозг человека. Как он обрабатывал бы данные? Это и есть нейронные сети.
Примеры из реальной жизни
На самом деле практически всё, с чем мы сталкиваемся ежедневно, так или иначе, является частью Big Data. Однако из-за такой обыденности мы не замечаем, что ежесекундно пользуемся этим инструментом, поэтому вся «магия» исчезает.

В качестве одного из самых близких каждому из нас примеров, можно привести получение прогноза погоды. Каждое утро мы просыпаемся и смотрим прогноз погоды, чтобы понять, что надеть. А в это время за значками с тучками и солнышками скрываются невероятные объёмы различной информации: замеры температуры, влажности, скорости ветра и других показателей, которые собираются на метеостанциях. Всю эту информацию собирают и передают сотни различных инструментов и сооружений. Обработать такие потоки не под силу обычными средствами, но благодаря Big Data мы знаем, когда нужно взять с собой зонтик. Пусть иногда и зря.
А вот самым популярным источником новостей из области больших данных в последнее время стал IBM Watson — сверхкомпьютер фирмы IBM, оснащённый уникальной системой искусственного интеллекта. Этот сверхкомпьютер готовит еду, лечит людей, а на досуге играет в «Свою игру».
Попробуйте это дома
В начале статьи я обещал, что вы сами сможете поиграть с большими данными. Чтобы принести практическую пользу миру, лучше всего вступить в ряды людей, которые при помощи своих компьютеров помогают искать новые планеты, изучать ДНК или просто обрабатывать данные. Поищите в интернете проекты по интересной вам тематике и присоединяйтесь к миллионам людей для продвижения науки.
А для остальных есть несколько других примеров по применению больших данных в реальной жизни.
Prisma
Да, та самая Prisma, которая делает с фотографиями вот так:
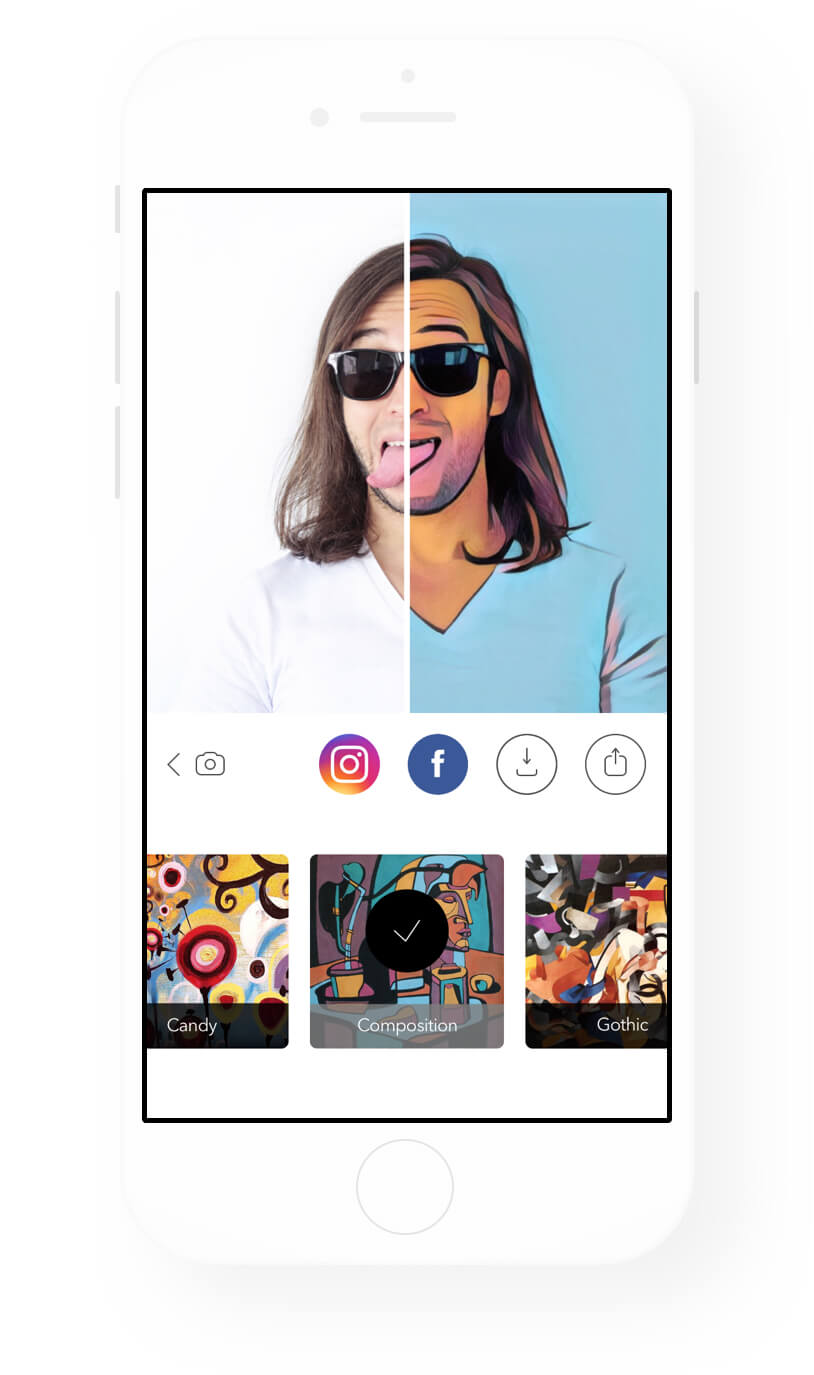
Prisma обрабатывает фотографии с помощью пресловутых нейронных сетей.
Установить Prisma.
Mya
Mya — сервис, который ищет информацию по заданной цели в автоматическом режиме, а поиск осуществляется при помощи IBM Watson, о котором я писал выше.
Почитать подробнее о Mya можно здесь.
Обзор Mya 1.0. Как автоматизировать поиск "Обзор Mya. Как автоматизировать поиск".
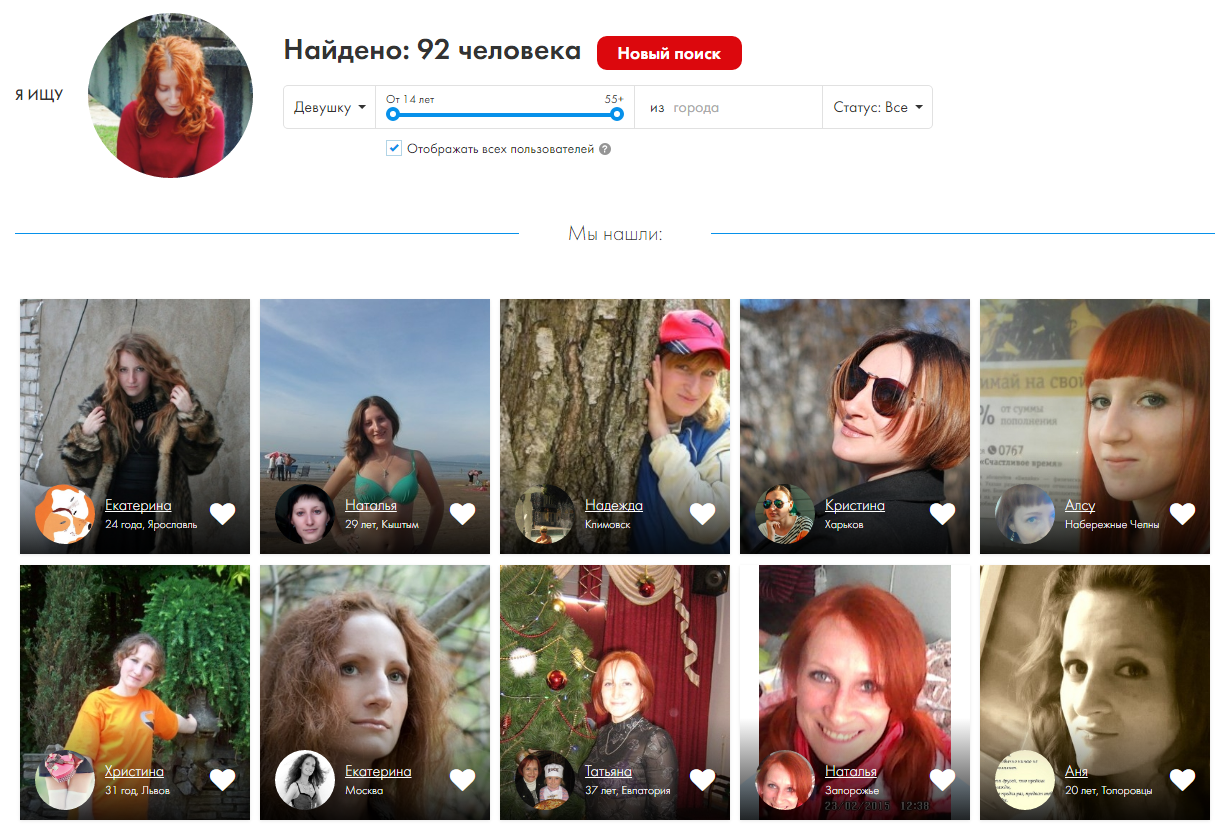
FindFace
FindFace — онлайн-сервис для поиска профиля во ВКонтакте по фотографии человека. Поиск работает благодаря обработке больших данных при помощи нейросети.
Большие данные окружают нас повсюду. Они не только поступают и обрабатываются каждую секунду, но и генерируются с невероятной скоростью. Сегодня за секунду человечество создаёт больше данных, чем за несколько десятилетий в прошлом веке. И этот пост тоже стал небольшим кусочком в огромном потоке Big Data.